Single-visit Mosaic Processing
Standard calibration pipeline processing focuses on aligning data taken as associations or as single exposures as closely to a standard astrometric coordinate frame as possible (see the DrizzlePac Handbook for full details). This involves alignment of very few images all taken under as identical conditions as possible; namely, detector, filter, guide stars, guiding mode, and so on. These observations were intended by the user to represent a single view of the object of interest in a way that allows for removal of as many calibration effects as possible.
Observations taken within a single visit, on the other hand, represent data intended to produce a multi-wavelength view of the objects in the desired field-of-view. Most of the time, those observations are taken using pairs of guide stars to provide a very stable field-of-view throughout the entire visit resulting in images which overlap almost perfectly. Unfortunately, this is not always possible due to increasing limitations of the aging telescope systems. The result is that an increasing number of visits are taken where observations drift and/or roll during the course of the visit or re-acquire at slightly different pointings from one orbit to the next. Whatever the reasons, data across each visit cannot automatically be assumed to align. Single-visit mosaic (SVM) processing attempts to correct these relative alignment errors and to align the data to an absolute astrometric frame so that all the data across all the filters used can be drizzled onto the same pixel grid.
Understanding the quality of the SVM products requires knowing what processing took place to generate that product, and more importantly, what limitations that processing may have had. The following sections provide the description of the single-visit processing. Definitions of a number of processing-specific terms used in this description can be found in the HAP Glossary.
Note
The products generated by SVM processing will be available through the archive
as HAP Products and can be found through the MAST Portal using the
search filter Project=HAP.
Single-Visit Products
All files processed as part of a single visit get renamed from the standard pipeline filenames into something which describes the data more clearly. The convention used for the names of these input and output files uses these components:
<propid> : the proposal ID for this visit
<obsetid> : the 2-digit visit ID from this proposal
<instr> : 3 or 4 letter designation of the instrument used for the observations
<detector> : name of the detector used for the observations
<filter> : hyphen-separated list of filter names used for the observations
<ipppssoo> : standard 8 character rootname for a single exposure defined by the pipeline
<ipppss> : standard 6 character designation of the <instr>/<propid>/<obsetid> for this visit
dr[cz].fits : suffix for drizzled products
fl[ct].fits : suffix for pipeline-calibrated files
hlet.fits : suffix for headerlet files containing the WCS solution used to create the final drizzle products/mosaics
<ipppss>_trl.txt : single-visit processing log files
point-cat.ecsv : suffix for point (aperture) photometric catalog products
segment-cat.ecsv : suffix for segment photometric catalog products
These components get combined to create filenames specific to each type of file being processed. The following table provides a complete list of all the products created as a result of single-visit processing.
Product |
File Type |
Filename for Files Produced |
|---|---|---|
Exposure |
drizzle product |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppssoo>_dr[cz].fits |
flat-field product |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppssoo>_fl[ct].fits |
|
headerlet file |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppssoo>_hlet.fits |
|
trailer file |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppssoo>_trl.txt |
|
preview (full size) |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppssoo>_dr[cz].jpg |
|
preview (thumbnail) |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppssoo>_dr[cz]_thumb.jpg |
|
Filter |
drizzle product |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppss>_dr[cz].fits |
point-source catalog |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppss>_point-cat.ecsv |
|
segment-source catalog |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppss>_segment-cat.ecsv |
|
trailer file |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppss>_trl.txt |
|
preview (full size) |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppss>_dr[cz].jpg |
|
preview (thumbnail) |
hst_<propid>_<obsetid>_<instr>_<detector>_<filter>_<ipppss>_dr[cz]_thumb.jpg |
|
Total |
drizzle product |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_dr[cz].fits |
point-source catalog |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_point-cat.ecsv |
|
segment-source catalog |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_segment-cat.ecsv |
|
trailer file |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_trl.txt |
|
preview (full size) |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_dr[cz].jpg |
|
preview (thumbnail) |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_dr[cz]_thumb.jpg |
|
color preview (full size) |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_<filters>_dr[cz].jpg |
|
color preview (thumbnail) |
hst_<propid>_<obsetid>_<instr>_<detector>_total_<ipppss>_<filters>_dr[cz]_thumb.jpg |
Primary User-Interface
One task has been written to perform the single-visit processing: runsinglehap.
It gets used by STScI to generate the single-visit products which
can be found in the Mikulski Archive for Space Telescopes (MAST) archive. This task
can also be run from the operating system command-line or from within a
Python session to reproduce those results, or with modification of the input
parameters, perhaps improve on the standard archived results. Full details on
how to run this task can be found in the description of the task at API for runsinglehap.
Processing Steps
Single-visit processing performed by runsinglehap
relies on the results of the standard astrometric
processing of the individual exposures and associations as the starting point
for alignment. This processing then follows these steps to create the final products:
Interpret the list of filenames for all exposures taken as part of a single visit and filter out images that cannot and/or should not be processed (e.g., exposure time of zero) from further processing.
Copy the pipeline-calibrated (FLT/FLC) files to the current directory for processing.
Rename the input files to conform to the single-visit naming conventions. (This step insures that the original pipeline results remain available in the archive unchanged)
Define what output products can be generated.
Align all exposures in a relative sense (all to each other).
Create a composite source catalog from all aligned input exposures.
Cross-match and fit this composite catalog to GAIA to determine new WCS solution.
Update renamed input exposures with results of alignment to GAIA.
Create each of the output products using the updated WCS solutions.
Note
It should be noted that processing is performed on a detector-by-detector basis; if a visit contains input data from n detectors, steps 5-9 will be executed serially n times to process the input images from each detector separately.
Processing the Input Data
SVM processing starts with a list of all the single exposures which were taken as part of a visit. Any associations which were defined by the proposal are ignored, since the visit itself gets treated, in essence, as a new association. The input files can be specified either using the poller file format used by the STScI automated processing or a file with a simple list of filenames (one filename per line).
Automated poller input file format
The automated processing performed to populate the MAST archive at STScI provides a file with the following format:
ic0s17h4q_flt.fits,12861,C0S,17,602.937317,F160W,IR,ic0s/ic0s17h4q/ic0s17h4q_flt.fits
ic0s17h5q_flt.fits,12861,C0S,17,602.937317,F160W,IR,ic0s/ic0s17h5q/ic0s17h5q_flt.fits
ic0s17h7q_flt.fits,12861,C0S,17,602.937317,F160W,IR,ic0s/ic0s17h7q/ic0s17h7q_flt.fits
ic0s17hhq_flt.fits,12861,C0S,17,602.937317,F160W,IR,ic0s/ic0s17hhq/ic0s17hhq_flt.fits
This example comes from the ‘ic0s1’ visit where the columns are:
exposure filename
proposal ID (numeric value)
program ID - ppp value from exposure filename
obset_id - visit number from proposal
exposure time of the exposure
filters used for the exposure, with muliple filters separated by a semicolon (e.g., F850LP;CLEAR2L)
detector used to take the exposure
location of the exposure in a local cache
Status of Input Data
The list of filenames which should be processed as a single-visit provides the raw science data for creating the new combined output products. However, these files need to be properly calibrated prior to SVM processing. Specifically, the exposures need to be:
fully calibrated using the instruments calibration software, such as
calacs.efor ACS andcalwf3.efor WFC3 data. This should also include CTE-correction for the images whenever possible.processed using
runastrodrizin order to apply the latest distortion model calibrations to the astrometry and to align the exposures as closely as possible to an external astrometric reference when possible.
These steps insure that the latest calibrations get applied to the data making it easier for the SVM processing to cross-match the data with minimal interference from artifacts in the data. In addition, the CTE-corrected versions of the data get used during pipeline processing in order to allow for better alignment of the exposures and to improve the photometry of the data as much as possible.
These processing steps can be verified in the input data using header keywords from the exposures
Header Keyword |
Valid Values |
Notes |
|---|---|---|
FLATCORR |
COMPLETED |
Completion of basic calibration |
DRIZCORR |
COMPLETED |
Completion of distortion calibration |
WCSNAME |
-FIT |
Successful a posteriori alignment |
-HSC30 |
Successful a priori alignment |
|
-GSC240 |
Successful a priori alignment |
The full set of possibilities for updated WCSs as reported using the WCSNAME keyword can be found in the description of the Interpreting WCS names.
As long as the input data meets these requirements, then SVM processing will have the best chance of success. Data which has not been able to be aligned successfully with an a priori or a posteriori solution can still be processed as part of a single-visit, however, the alignment may be more difficult to determine due to the larger uncertainties for HST pointing prior to October 2017.
Filtering the input data
Not all HST imaging observations can be aligned using SVM processing. Observations taken, for example, in SPATIAL SCAN mode result in sources which can not be aligned. The haputils.analyze module evaluates all input exposures using these header keywords for the stated rejection criteria.
Header Keyword |
Values Which Trigger Rejection |
Explanation |
|---|---|---|
OBSTYPE |
(not IMAGING) |
Tyically only Imaging mode data is processed with the |
exception of SPECTROSCOPIC Grism and Prism images |
||
MTFLAG |
T |
No moving targets, WCS and background sources vary |
SCAN_TYP |
C or D (or not N) |
Can not align streaked sources |
FILTER or FILTER1, FILTER2 |
BLOCK |
Internal calibration of SBC detector |
EXPTIME |
0 |
no exposure time, no data to align |
TARGNAME |
DARK, TUNGSTEN, BIAS, FLAT, |
No alignable external sources in these calibration modes |
EARTH-CALIB, DEUTERIUM |
No alignable external sources in these calibration modes |
|
CHINJECT |
not NONE |
No alignable external sources in these calibration modes |
Any observation which meets any of these criteria are flagged to be ignored (not processed). An exception has been allowed for data where the OBSTYPE keyword is equal to SPECTROSCOPIC and FILTER (or FILTER1, FILTER2) is equal to Grism or Prism. The Grism/Prism SVM FLT/FLC data are retained to reconcile the active WCS between the Grism/Prism images and any valid direct exposures obtained with the same detector. In addition, any data taken where the FGSLOCK keyword contains ‘COARSE’ or ‘GY’ will be flagged as potentially compromised in the comments generated during processing.
All observations which are alignable based on these criteria are then passed along as a table to create the SVM products. Those inputs which can be processed are then copied and renamed using the Single-Visit Products. This insures that no SVM processing will affect or otherwise modify the original pipeline-processed input files. Only the SVM named input files will be updated with new SVM-aligned WCS solutions and then used to produce the drizzle products.
Defining the Output Products
The table with the set of observations which can be processed now gets interpreted.
The goal is to identify what exposures can be combined to create unique products.
This grouping will be used to create the product list.
The product list is a Python list of
HAPProduct objects, described in drizzlepac.haputils.product API docs,
which represent each and every output product to be created for the visit.
While the specifics of each Product class vary, representative Product
instances contain:
list of filenames for all input exposures that will contribute to the output drizzle product
WCS for output drizzle product
pre-defined names for all output files associated with this Product including:
drizzle-combined image
point-source catalog determined from the drizzle-combined image
segmentation-based catalog determined from the drizzle-combined image
astrometric catalog used to align the input exposures
output trailer (aka log) file recording the processing stages
methods for:
determining average number of images per pixel
defining the final WCS
aligning the exposures to an astrometric reference (GAIA)
applying the selected parameters to
AstroDrizzledrizzling the inputs to create the output drizzle product
determining the source catalogs from the drizzle product
This interpretation of the list of input filenames gets performed using the
code in drizzlepac.haputils.poller_utils by
grouping similar observations. The rules used for grouping the inputs into output
products result in outputs which have the same detector and filter. These output
products are referred to as filter products defined as a product/FilterProduct
instance.
All exposures for a single detector are also identified and grouped to
define a total product using the product/TotalProduct class.
This total product drizzle image provides the deepest available
view of the field-of-view from this visit which will be used to produce the master
catalog of sources for this visit. The master catalog of source positions will
be used to perform photometry on each exposure, whether the source can be identified
in the exposure at that position or not. This forced photometry results in
limits for the photometry in cases where the sources are not bright enough to be
identified in a given filter.
Two separate source catalogs for each filter are also pre-defined; namely,
a point-source catalog derived using
photutilsDAOStarFindera segmentation-based catalog derived using
photutilssegmentation code
These two catalogs provide complimentary views of each field-of-view to try to highlight all types of compact sources found in the exposures.
Example Visit
For example, a relatively simple visit of a fairly bright and crowded field with 6 F555W exposures (two 15-second and four 30-second exposures) and 6 F814W exposures (two 5-second and four 15-second exposures) would result in the definition of these output products:
a drizzled image for each separate exposure
a WCS updated FLT/FLC image for each separate exposure
a headerlet file for each separate exposure
a trailer file for each separate exposure
a single F555W product (a drizzled filter image and corresponding trailer file)
a single F814W product (a drizzled filter image and corresponding trailer file)
a single total product (a drizzled total detection image and corresponding trailer file)
a point-source catalog for the F555W product
a segmentation-based source catalog for the F555W product
a point-source catalog for the F814W product
a segmentation-based source catalog for the F814W product
a point-source catalog for the total product
a segmentation-based catalog for the total product
The function drizzlepac.haputils.poller_utils.interpret_obset_input() serves as the sole
interface for interpreting either the input poller file which contains exposure
information for a visit or a file which contains dataset names, one per line.
A basic tree is created (as a dictionary of dictionaries) by this function where the
output exposures are identified along with all the names of the input exposures.
This tree then serves as the basis for organizing the rest of the SVM processing.
In addition to defining what output products need to be generated, all the SVM products names are defined using the Single-Visit Products. This insures that all the output products have filenames which are not only unique, but also understandable (if a bit long) that are easily grouped on disk.
Aligning the Input Data
All input exposures should have already been aligned either individually or by association table as close to GAIA as possible during standard pipeline calibration processing. However, each exposure or association (of exposures) can be aligned to slightly different fits or catalogs due to differences in the source objects which can be identified in each separate exposure. The primary goal of SVM processing is to refine this alignment so that all exposures in the visit for the same detector (those exposures which contribute to each total product) share the same WCS (pixels on the sky).
Alignment of all the exposures for a total product uses some of the same low-level alignment code as the standard calibration pipeline, the command sequencing and specific process is done by the align_to_gaia() method in the HAPProduct base class in the product.py module. The basic steps it follows is:
generate a source catalog for each exposure (using haputils.astrometric_utils)
obtain the WCS from each exposure
perform a relative fit between the exposures using
tweakwcsobtain an astrometric reference catalog for the field-of-view
perform a final fit of all the exposures at once to the astrometric catalog
update each WCS with the final corrected WCS generated by
tweakwcs
A reference image is chosen among the exposures based on maximizing image overlap. The code choses one of the two images with the most overlap with the rest of the exposures. This code is also called from the tweakwcs package.
This basic process gets performed using different reference catalog and different fitting modes until it obtains a successful fit. The fitting loops over the following catalogs in order of priority:
GAIAeDR3
GSC242
2MASS
The field being fit may not have any GAIA sources, however, it may instead be dominated by extra-galactic sources measured by the PAN-STARRs project and included in the GSC242 catalog. Thus, the fit to GAIA may not result in any cross-matches due to lack of GAIA sources, so the algorithm would continue on to try to fit to the GSC242 catalog where it obtains enough cross-matches for a successful fit. This would immediately cause the fitting algorithm to end with this fit to the GSC242 catalog as the one to be used to update the WCS solutions of the input images for the visit.
While attempting to fit to each catalog, the algorithm tries fitting using the following geometries (again, in order of priority):
rscale : full 6-parameter linear fit with skew terms
rshift : 4 parameter linear fit with rotation and scale the same in X and Y
shift : only fit for shift in X and Y, no rotation or scale terms
For example, should there only be 5 cross-matches between the image and the GSC242 catalog, then the ‘rscale’ fit would fail due to a requirement set by the code to only use ‘rscale’ with >=6 cross-matches. Thus, the ‘rscale’ fit would fail, and the algorithm would then try ‘rshift’ which would be successful. As a result, the GSC242 catalog fit using ‘rshift’ would be used to update the WCS solutions for all the input images.
The limits for performing the relative alignment and absolute fit to the astrometric catalog (defaults to GAIAeDR3) are lower under the expectation that large offsets (> 0.5 arcseconds) have already been removed in the pipeline processing. This makes the SVM alignment more robust across a wider range of types of fields-of-view. The final updated WCS will be provided with a name that reflects this cross-filter alignment using -FIT_SVM_<catalog name> as the final half of the WCSNAME keyword. More details on the WCS naming conventions can be found in the Interpreting WCS names section.
Creating the Output Products
Successful alignment of the exposures allows them to be combined into the
pre-defined output products; primarily, the filter products and the total products.
These products get created using drizzlepac.astrodrizzle.AstroDrizzle().
Selecting Drizzle Parameters
Optimal parameters for creating every possible type of output product or mosaic would require knowledge of not only the input exposures, but also expert knowledge of the science. Parameters optimized for one science goal may not be optimal for another science goal. Therefore, automated pipeline processing has defined a basic set of parameters which will result in a reasonably consistent set of products as opposed to trying to optimize for any specific science case.
The default parameters have been included as part of the drizzlepac package
in the drizzlepac/pars/hap_pars directory. Index JSON files provide the options
that have been developed for selecting the best available default parameter set
for processing. The INDEX JSON files point to different parameter files (also in
JSON format) that are also stored in sub-directories which are organized by instrument
and detector.
Selection criteria are also listed in these Index JSON files for each step in the SVM processing pipeline; namely,
alignment
astrodrizzle
catalog generation
quality control
Initially, only the astrodrizzle step defines any selection criteria for use in processing. The criteria is based on the number of images being combined for the specific instrument and detector of the exposures.
The SVM processing interprets the input data and verifies what input data can be processed. At that point, the code determines what selection criteria apply to the data and uses that to obtain the appropriate parameter settings for the processing steps. Applying the selection to obtain the appropriate parameter file simply requires matching up the key in the JSON file with the selection information. Depending on the detector, selection information can take the form of the number of input observations, the date that the observations were taken, the central filter wavelength, or the dispersive element type. For example, a filter product would end up using the filter_basic criteria, while an 8 exposure ACS/WFC association would end up selecting the acs_wfc_any_n6 entry. For more details on the alignment configuration files, see the Detector Configuration Files section.
User-customization of Parameters
The parameter configuration files now included in the drizzlepac package are
designed to be easily customized for manual processing with both runastrodriz
(pipeline astrometry processing) and runsinglehap (SVM processing). These
ASCII JSON files can be edited prior to manual reprocessing to include whatever
custom settings would best suit the science needs of the research being performed
with the data. Template SVM processing pipeline parameter files populated with default
values can be created using generate_custom_svm_mvm_param_file. For details on how these
parameter files can be created, please refer to the haputils.generate_custom_svm_mvm_param_file
documentation.
Defining the Output WCS
The SVM processing steps through the product list to generate each of the pre-defined products one at a time after the input exposures have all been aligned. One of the primary goals of SVM processing is to produce combined images which share the same WCS for all the data from the same detector. This simply requires defining a common WCS which can be used to define the output for all the filter products from the visit.
The common WCS, or metawcs, gets defined by reading in all the WCS definitions
as stwcs.wcsutil.HSTWCS objects
for all the input exposures taken with the same instrument in the visit. This
list of HSTWCS objects then gets fed to stwcs.distortion.utils.output_wcs,
the same function used by AstroDrizzle to define the default output WCS when
the user does not specify one before-hand. This results in the definition of a
WCS which spans the entire field-of-view for all the input exposures with the same
plate scale and orientation as the first HSTWCS in the input list. This metawcs
then gets used to define the shape, size and WCS pointing for all drizzle products
taken with the same detector in the visit.
Handling Special Images
Grism and Prism images are acquired as part of a visit, in conjunction with their direct image counterparts, and classified as spectroscopic data. It is beneficial for these images to share a common WCS with the corresponding direct images from the same detector in the visit. Because the Grism/Prism data cannot be used in the alignment procedure due to the nature of the data, the best WCS solution that can be generated for these images is an a priori solution. An a priori solution has been determined for essentially all HST data by correcting the coordinates of the guide stars that were used for the observation to the coordinates of the same guide stars as determined by GAIA, in this case. The actual image pixels have not been used in the WCS determination. The WCSNAME for this a priori solution is of the form:
<Starting WCS>-<Astrometric Catalog>
For example,
'IDC_0461802ej-GSC240'
where the Astrometric Catalog refers to the specific astrometric catalog used to correct the guide star positions.
During SVM processing, all the WCS solutions in common to all of the Grism/Prism and direct images from the same detector in the visit are gathered and matched against a list of prioritized WCS solutions, where the preferred solution is of the form IDC_?????????-GSC240 and the IDC_????????? represents the particular IDCTAB reference file. Once a common WCS solution is determined, the active (aka primary) WCS solution for the Grism/Prism and direct images from the same detector is then set to this common solution. Any previously active WCS for the image that is not already stored in the image will be archived as a new WCS headerlet extension, unless the solution as identified by the HDRNAME, already exists as a headerlet.
The only SVM processing performed on or with Grism/Prism images is with respect to the potential update to a common active WCS with its corresponding direct images. These images are not used in any SVM processing steps. Effectively the images are only processed to an exposure level product. If the Grism/Prism images have no corresponding direct images acquired with the same detector, then the process of reconciling the WCS of the images in the visit is not done.
Ramp images are utilized only in the alignment to GAIA stage of the processing, thereby contributing to the computation of the metawcs of the total detection image based upon all exposures in the visit. During this process it is possible the active WCS of each Ramp exposure has been updated. The Ramp exposures, similar to the Grism/Prism images, are only processed to an exposure level product.
Drizzling
Each output product gets created using AstroDrizzle. This step:
combines all the input exposures associated with the product
uses the parameters read in from the configuration files
defines the output image using the metawcs WCS definition
writes out a multi-extension FITS (MEF) file for the drizzled image using the pre-defined name
This drizzled output image has the same structure as the standard pipeline drizzle products; namely,
PRIMARY extension: all information common to the product such as instrument and detector.
SCI extension: the drizzled science image along with header keywords describing the combined array such as total exposure time.
WHT extension: an array reporting the drizzled weight for each pixel
CON extension: an array reporting what input exposures contributed to each output pixel
The headers of each extension gets defined as using the fitsblender software with
much the same rules used to create the standard pipeline drizzle product headers.
In short, it uses simple rules files to determine what keywords should be kept in
the output headers from all the input exposures, and how to select or compute the
value from all the input headers for each keyword.
Unique SVM Keywords
A small set of keywords have been added to the standard drizzle headers to reflect the unique characteristics of the SVM products. These keywords are:
Defining the Footprint
The S_REGION keyword records the footprint of the final drizzle image as it appears
on the sky as a list of RA and Dec positions ordered in a counter-clockwise manner.
These positions outline only those pixels which have been observed by HST, not
just the rectangular shape of the final drizzle array. This allows the archive
to provide a preview of the drizzle product footprints in their all-sky map to
assist users in selecting the data most suited for their search.
The computation of this keyword relies on creating a filled shape, finding the border pixels of the shape, ordering the vertices in a counter-clockwise manner, and simplifying the shape by removing unnecessary vertices. The resulting vertices are then converted to sky coordinates (degrees). Our strategy relies on two complementary techniques named dilation and erosion, which add and remove pixels, respectively.
In the code, the top level call functions are in processing_utils
where the compute_sregion() function calls the find_footprint function.
This function makes calls to two methods in the SkyFootprint class in cell_utils
that build up a total mask (extract_mask), and find the vertices/corners of that mask
(find_corners).
Dilation and Erosion
We use the mathematical morphology operations of binary erosion and binary dilation in different orders for two purposes. Using erosion and then dilation (the morphological “opening” operation) removes isolated pixels and narrow tendrils. This has the effect of isolating islands of pixels that are thinly connected to one another and removing noise. Doing the opposite, dilation and then erosion (the morphological “closing” operation), fills in small holes and gaps to join islands and smooth the outer edge to some degree.
Extracting a Mask
Extracting the the mask first involves using a ndimage.binary_fill_holes to fill in any holes surrounded by data. The code then uses dilation to keep edge features while smoothing the outer edge. Erosion is then used to get a mask that has a similar shape and size to the original mask. We then combine the resulting mask with the original mask to ensure we retain features that touch the image edges.
Finding Border Pixels
The code traces the edge of the footprint to isolate only the edge pixels. It then uses erosion and then dilation to remove noise and island pixels. It then applies a gaussian filter to the edge pixels to ultimately create a smoother S_REGION. To find all the edge pixels, an eroded version of the mask is subtracted from the mask, which leaves behind only the pixels around the edge. A box search algorithm is used to connect the edge pixels in a path going counter-clockwise around the image edge. Finally, the resulting edge path is simplified.
Simplifying the Border
In order to decrease the number of vertices for our S_REGION we use the simplify-polyline package. A call to simplify-polyline.simplify looks at each set of three consecutive vertices and determines if the errors in the line changes significantly when the middle pixel is removed. If it is below an set error (min_dist), the code removes the pixel. This algorithm is repeated until no more pixels are found to remove. It should be noted that in later iterations, these three pixels can be far apart. The result is that unnecessary pixels are removed and more complicated edge shapes are simplified.
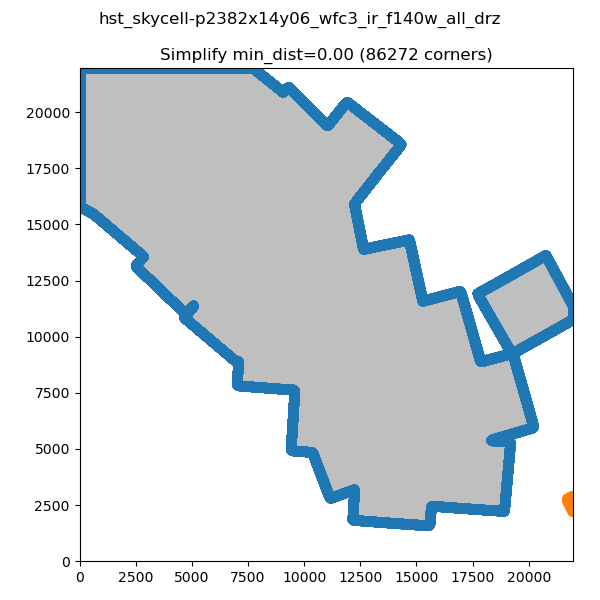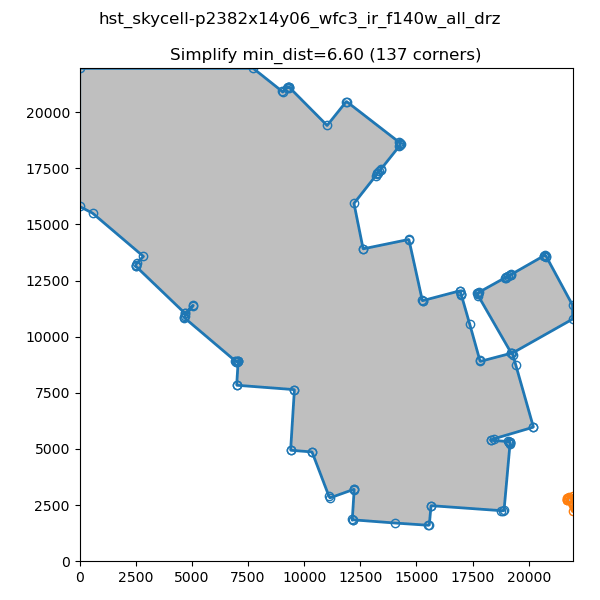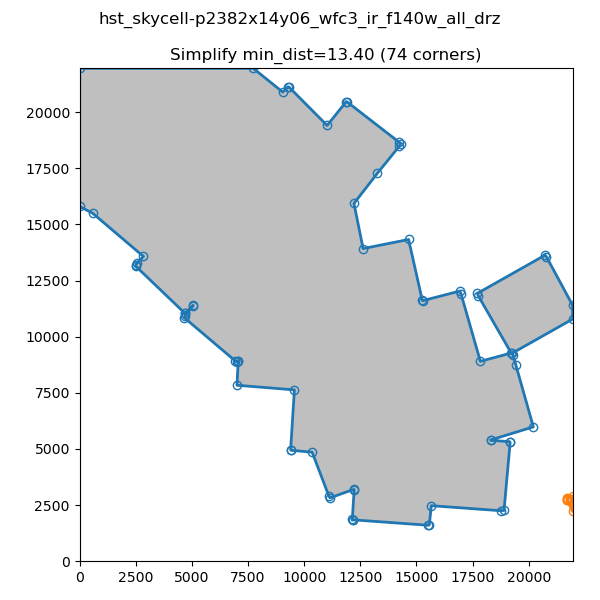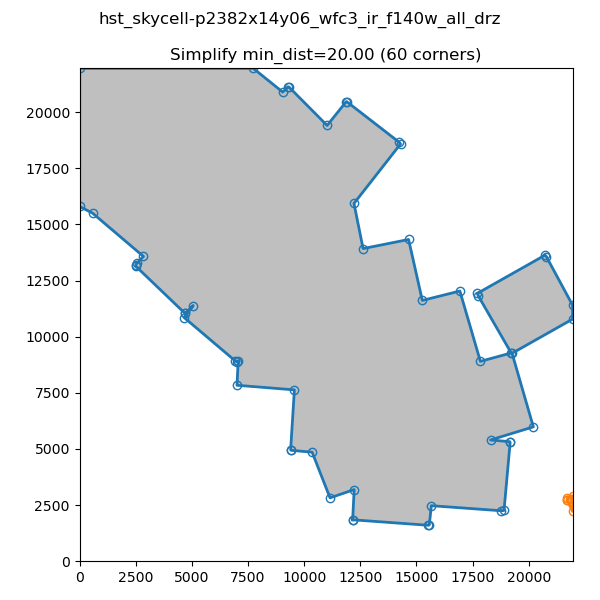
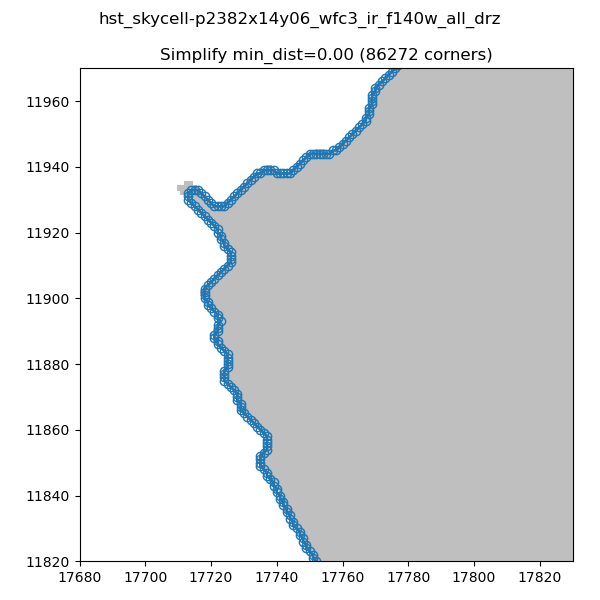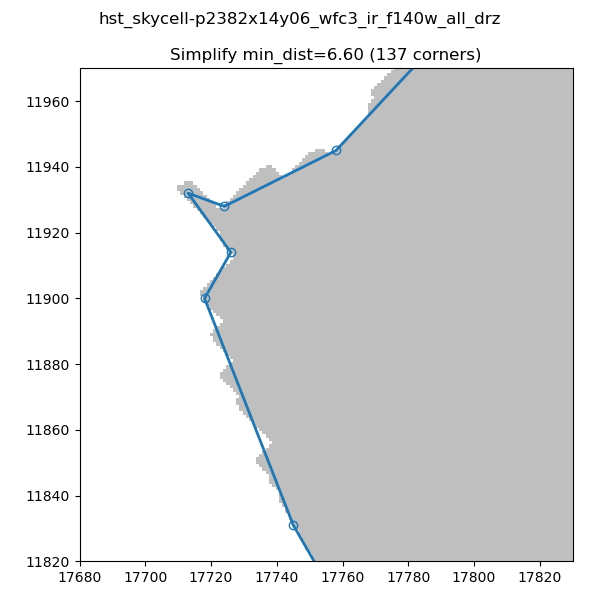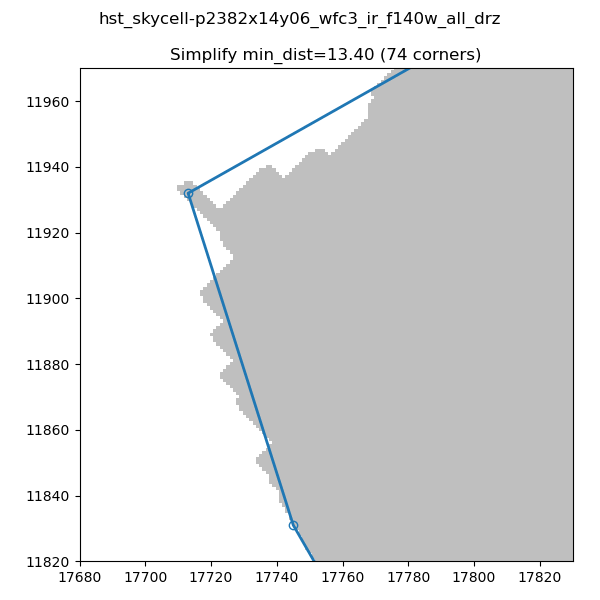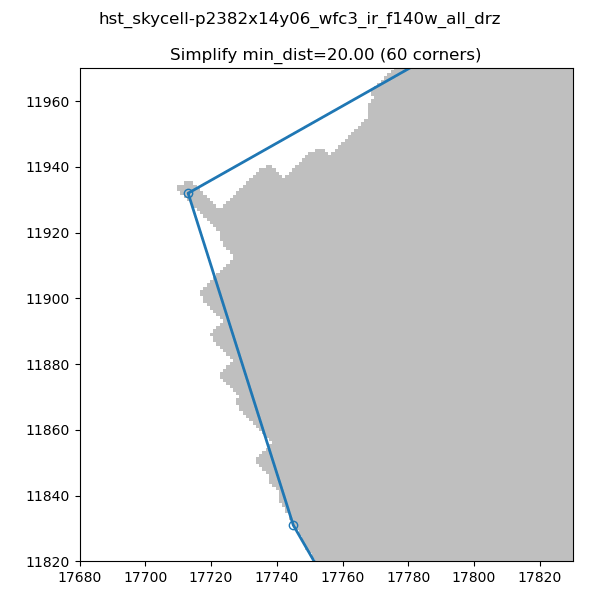
Note
This function also gets called during standard-pipeline processing to populate the
S_REGION keyword in all calibrated FLC/FLT files as well. For FLT/FLC files,
the underlying code for calculating the s_region is the astropy.wcs function
calc_footprint().
Skycell Information
The pipeline (ipppssoot) and SVM processing both add the SKYCELL keyword to the headers of the input FLT(C) and drizzled DRZ(C) products. This keyword includes all of the skycells that the input exposures overlap.
Note
The SKYCELL keyword values can differ between the pipeline and SVM products as the values depend on the WCSNAME of the input exposures.
Catalog Generation
SVM processing does not stop with the creation of the output drizzled images like the standard calibration pipeline. Instead, it derives 2 separate source catalogs from each drizzled filter product to provide a standardized measure of each visit. For more details on how the catalogs are produced, please refer to the Catalog Generation documentation page.
Catalog Quality Control
All detected sources are not created equal. Raw source catalogs typically contain a mix of scientifically legitimate point sources, scientifically legitimate extended sources, and scientifically dubious sources (those likely impacted by low signal-to-noise ratio, detector artifacts, saturation, cosmic rays, etc.). The last set of algorithms run by SVM processing classifies each detected source into one or more of these groups and assigns each source a classification value, known as a flag. Based on the flag value, sources that are obviously scientifically dubious are filtered out and not written to the final source catalogs. More details on this process can be found in section 2.4.2: Determination of Flag Values of the catalog generation documentation page.